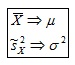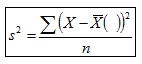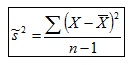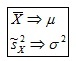Pruebas de hipótesis para una varianza Es un procedimiento para juzgar si una propiedad que se supone cumple una población estadística es compatible con lo observado en una muestra de dicha población en este caso la varianza, para ello formularemos dos Hipótesis (llamada "Hipótesis Nula") y (llamada "Hipótesis Alternativa"), con ellas realizaremos una o mas pruebas, para tratar de encontrar cual deberíamos rechazar. En este procedimiento lo que buscamos es, mediante unos criterios de rechazo preestablecidos, tratar de desmentir nuestra “Hipótesis Nula” por lo cual tomaríamos la “Hipótesis alternativa”, de lo contrario no rechazaríamos nuestra ”Hipótesis Nula” y desecharíamos la ”Hipótesis.
la función Chi cuadrado tiene una distribución de datos de la siguiente forma:
Lo que nos da a entender que a diferencia de las distribuciones normales y t Student que hemos venido trabajando, Chi cuadrado no es simétrica, es por esto que cuando hallamos los limites para una prueba de hipótesis a dos colas, debemos hallar el chi cuadrado de y ,a diferencia de las otras dos distribuciones mencionadas anteriormente, en las cuales solo era necesario calcular uno de estos valores y el otro limite se conocería multiplicando el hallado por 1. A continuación enseñaremos a manejar la tabla de la distribución Chi cuadrado. En esta nos dan dos parámetros, el primero es en el que nos relaciona con , y el segundo que representa los grados de libertad, para efectos prácticos, en la tabla se busca de la siguiente forma:
Lo que nos da a entender que a diferencia de las distribuciones normales y t Student que hemos venido trabajando, Chi cuadrado no es simétrica, es por esto que cuando hallamos los limites para una prueba de hipótesis a dos colas, debemos hallar el chi cuadrado de y ,a diferencia de las otras dos distribuciones mencionadas anteriormente, en las cuales solo era necesario calcular uno de estos valores y el otro limite se conocería multiplicando el hallado por 1. A continuación enseñaremos a manejar la tabla de la distribución Chi cuadrado. En esta nos dan dos parámetros, el primero es en el que nos relaciona con , y el segundo que representa los grados de libertad, para efectos prácticos, en la tabla se busca de la siguiente forma:
PRUEBA DE HIPOTESIS PARA MEDIAS
En vez de estimar el valor de un parámetro, a veces se debe decidir si una afirmación relativa a un parámetro es verdadera o falsa. Es decir, probar una hipótesis relativa a un parámetro. Se realiza una prueba de hipótesis cuando se desea probar una afirmación realizada acerca de un parámetro o parámetros de una población.
Una hipótesis es un enunciado acerca del valor de un parámetro (media, proporción, etc.).
Prueba de Hipótesis es un procedimiento basado en evidencia muestral (estadístico) y en la teoría de probabilidad (distribución muestral del estadístico) para determinar si una hipótesis es razonable y no debe rechazarse, o si es irrazonable y debe ser rechazada.
La hipótesis de que el parámetro de la población es igual a un valor determinado se conoce como hipótesis nula. Una hipótesis nula es siempre una de status quo o de no diferencia.

En toda prueba de hipótesis se presentan 3 casos de zonas críticas o llamadas también zonas de rechazo de la hipótesis nula, estos casos son los siguientes:
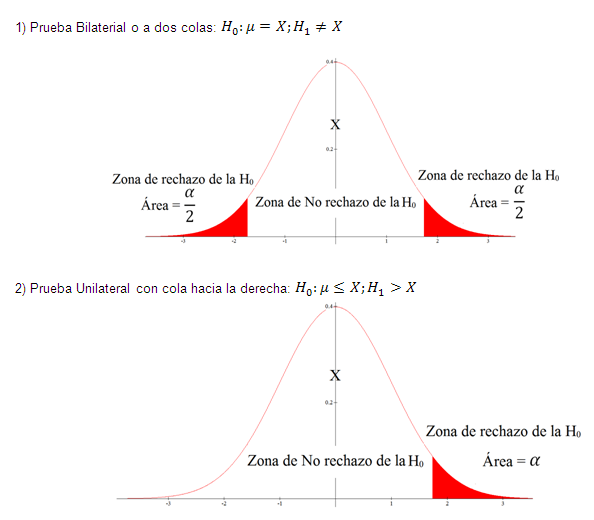

En toda prueba de hipótesis se pueden cometer 2 tipos de errores:

Prueba medias de una muestra
Se utiliza una prueba de una muestra para probar una afirmación con respecto a una media de una población única.

Nota: Se considera práctico utilizar la distribución t solamente cuando se requiera que el tamaño de la muestra sea menor de 30, ya que para muestras más grandes los valores t y z son aproximadamente iguales, y es posible emplear la distribución normal en lugar de la distribución t.

Ejemplos ilustrativos:
1) La duración media de una muestra de 300 focos producidos por una compañía resulta ser de 1620 horas.

Como se tiene como dato el tamaño de la población se tiene que verificar si cumple con la condición para utilizar el factor finito de corrección.


El gráfico elaborado con Winstats y Paint se muestra en la siguiente imagen:

2) La duración media de lámparas producidas por una compañía han sido en el pasado de 1120 horas. Una muestra de 8 lámparas de la producciónactual dio una duración media de 1070 horas con una desviación típica de 125 horas.

Los cálculos en Excel se muestran en la siguiente imagen:

El gráfico elaborado con Winstats y Paint se muestra en la siguiente imagen:

Prueba medias de dos muestras
Las pruebas de dos muestras se utilizan para decidir si las medias de dos poblaciones son iguales. Se requieren dos muestras independientes, una de cada una de las dos poblaciones. Considérese, por ejemplo, una compañía investigadora que experimentan con dos diferentes mezclas de pintura, para ver si se puede modificar el tiempo de secado de una pintura para uso doméstico. Cada mezcla es probada un determinado número de veces, y comparados posteriormente los tiempos medios de secado de las dos muestras. Una parece ser superior, ya que su tiempo medio de secado (muestra) es 30 minutos menor que el de la otra muestra.
Pero, ¿son realmente diferentes los tiempos medios de secado de las dos pinturas, o esta diferencia muestral es nada más la variación aleatoria que se espera, aun cuando las dos fórmulas presentan idénticos tiempos medios de secado? Una vez más, las diferencias casuales se deben distinguir de las diferencias reales.
Con frecuencia se utilizan pruebas de dos muestras para comparar dos métodos de enseñanza, dos marcas, dos ciudades, dos distritos escolares y otras cosas semejantes.
La hipótesis nula puede establecer que las dos poblaciones tienen medias iguales:

Para tamaños más pequeños de muestra, Z estará distribuida normalmente sólo si las dos poblaciones que se muestrean también lo están.

Ejemplo ilustrativo
La media de las calificaciones de dos muestras de 15 estudiantes de primer semestre en la asignatura de Estadística de la universidad UTN resulta ser de 7 y 8,5. Se sabe que la desviación típica de las calificaciones en esta asignatura fue en el pasado de 1,5.

Los cálculos en Excel se muestran en la siguiente figura:


PRUEBA DE HIPÓTESIS PARA PROPORCIONES
El procedimiento para la prueba de hipótesis de proporciones
es el siguiente:
1.
Especifica
la hipótesis nula y alternativa.
Hipótesis Nula: 
Hipótesis Alternativa:  ,
,
donde P = la proporción de clientes con ingresos
familiares anuales de $200,000 o más.
2.
Específica
el nivel de significación,  , permitido. Para una
, permitido. Para una  , el valor de tabla de Z para
una prueba de una sola cola es igual a
1.64.
, el valor de tabla de Z para
una prueba de una sola cola es igual a
1.64.
3.
Calcula
el error estándar de la proporción específicada en la hipótesis nula.

donde:
p =
proporción especificada en la hipótesis nula.
n =
tamaño de la muestra.
Por consiguiente:

4.
Calcula
la estadística de prueba:


5.
La hipótesis nula se rechaza porque el valor de la Z calculada
es mayor que el valor crítico Z . El banco puede concluir con un 95 por ciento de
confianza  que más de un 60 por
ciento de sus clientes tienen ingresos familiares de $200,000 o más. La
administración puede introducir el nuevo paquete de servicios orientado a este
grupo.
que más de un 60 por
ciento de sus clientes tienen ingresos familiares de $200,000 o más. La
administración puede introducir el nuevo paquete de servicios orientado a este
grupo.